
摘要:本文基于近期网络流传的公开数据,对缅甸“诈骗”相关失踪人群进行结构化分析与可视化总结。
星星回家:缅甸诈骗相关失踪人群数据分析(LLM 辅助)
摘要:基于公开互助档案,梳理受骗画像与地域分布。
作者姓名: 曹越洋
所属院校: 香港大学数据与系统工程系
角色: 独立分析师(数据获取、标注、可视化、报告)
联系方式: andy.caoyueyang[at]gmail[dot]com
时间: 2025年1月
一、目标和结论
基于公开“星星回家互助档案”的表格中提取结构化信息,快速完成受骗原因/时间/地域/画像的统计与可视化,验证 LLM 辅助标注在小样本社会议题上的效率/成本优势与局限。
数据来源与合规
- 来源: 网络公开 Excel(获取日期:2025-01-14)
- 处理: 仅做聚合与匿名化展示,不含任何可识别个人信息(PII)。
- 使用限制与免责声明: 用于公益与研究讨论,不作商业用途;结论受数据质量与收集偏差影响。
关键发现
- 画像: 95% 为男性;80% 在 18–35 岁。
- 地域: 云南 613 人,72.53% 集中在西双版纳。
- 原因: 88.49% 因“高薪诱惑”受骗。
二、项目概况
2025年1月14日由于演员“王星被骗泰国事件”的热议,网络上流传一份在线文档——“星星回家互助档案”,自发下载公开文档,开展独立探索性分析。
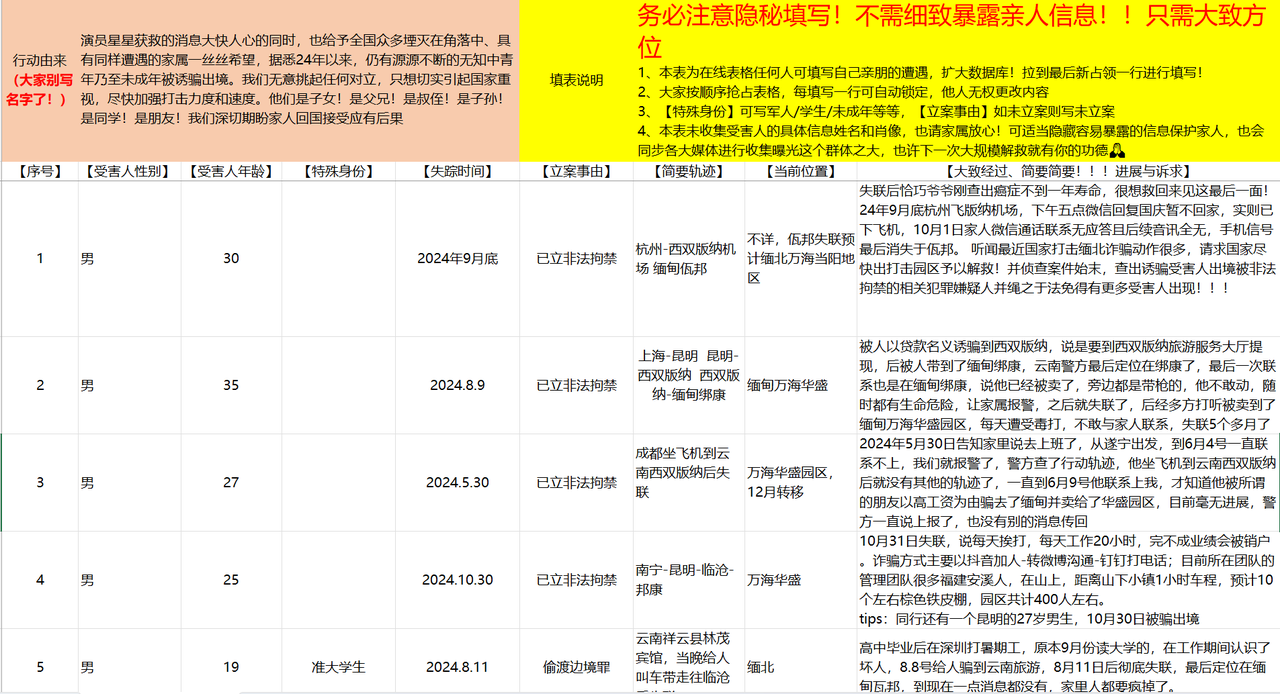
星星回家互助档案 Excel 数据源
分析方法
- 数据清洗(Python)
- 使用
pandas读取 Excel,去除冗余列,标准化日期为「YY.MM」格式。 - 导出为结构化 TXT 文件,便于后续在 LLM 中直接复制粘贴。
- 使用
- LLM 辅助分类(Gemini Web)
- 将 TXT 数据分批粘贴到 Gemini Pro 2.0,设计提示词要求模型输出“受骗原因、时间、地域”等字段。
- 多轮提示迭代,要求结果保持 CSV 友好格式,便于后续统计。
- 输出结果 Copy 回本地,统一转为 CSV。
- 结果统计与可视化(Excel + Tableau)
- 在 Excel 中完成基础筛选与计数。
- 在 Tableau 中制作地图、柱状图、饼图,展示地域分布、时间趋势、人口画像。
方法总结
- 优势: 相比传统 NLP 方法,LLM 标注流程更灵活,成本更低,能快速应对小规模社会议题分析。
- 局限: 分类存在模糊与少量幻觉,需要人工抽样复核与规则修正。
三、全流程细节
第一步:数据本地化清洗
首先将 Excel 文档下载到本地,使用 Python 将文档内容导出为 txt,便于 Copy 到 LLM 里面进行分析。
1 | import pandas as pd |
得到结构化的 txt 文档:
结构化 TXT 文档示例
第二步:数据导入 LLM 中处理
由于数据量不大,无需调用 API,直接在 Web 端即可得到分析后的结果。将文本内容直接 Copy 到 Google Ai Studio 的 Gemini Pro 2.0 中进行反复提问。
提示词示例:
以下是一些受骗数据,请你对受骗原因进行分类,
根据下列分类方式请你根据原文内容逐条输出一个可以转化为 csv 文档的 txt 文本,包括两列,例如高薪诱惑类:
虚假招聘/高薪工作: 这是最常见的诱骗方式。骗子通过网络、朋友或熟人发布虚假招聘信息,承诺高薪、轻松的工作,引诱受害者前往边境地区,然后将其控制。
…按照你上述对受骗原因的分类方式,请你逐条输出一个可以转化为 csv 文档的 txt 文本,包括三列,例如:
序号,失踪时间,受骗原因
1,”24.11”,”高薪职位:具体描述”
2,”24.08”,”网络交友:具体描述”其中失踪日期要按照我给的格式,即”年份.月份“即可,现在先试着输出前10条。
…
”受骗原因的部分太长了,我需要你提取归纳一下,抽象一点但是保留一些细节,按照我的要求再试着提取前5个“要求再来一次。
很好,现在试着从1开始逐条输出至全部。
在 LLM 中得到相应的结果,Copy 到本地 txt 中:
LLM 输出结果示例
同理,可以得到时间、国内地级市、年龄段、具体原因等数据。全部统计完成后转化为 Excel 文档: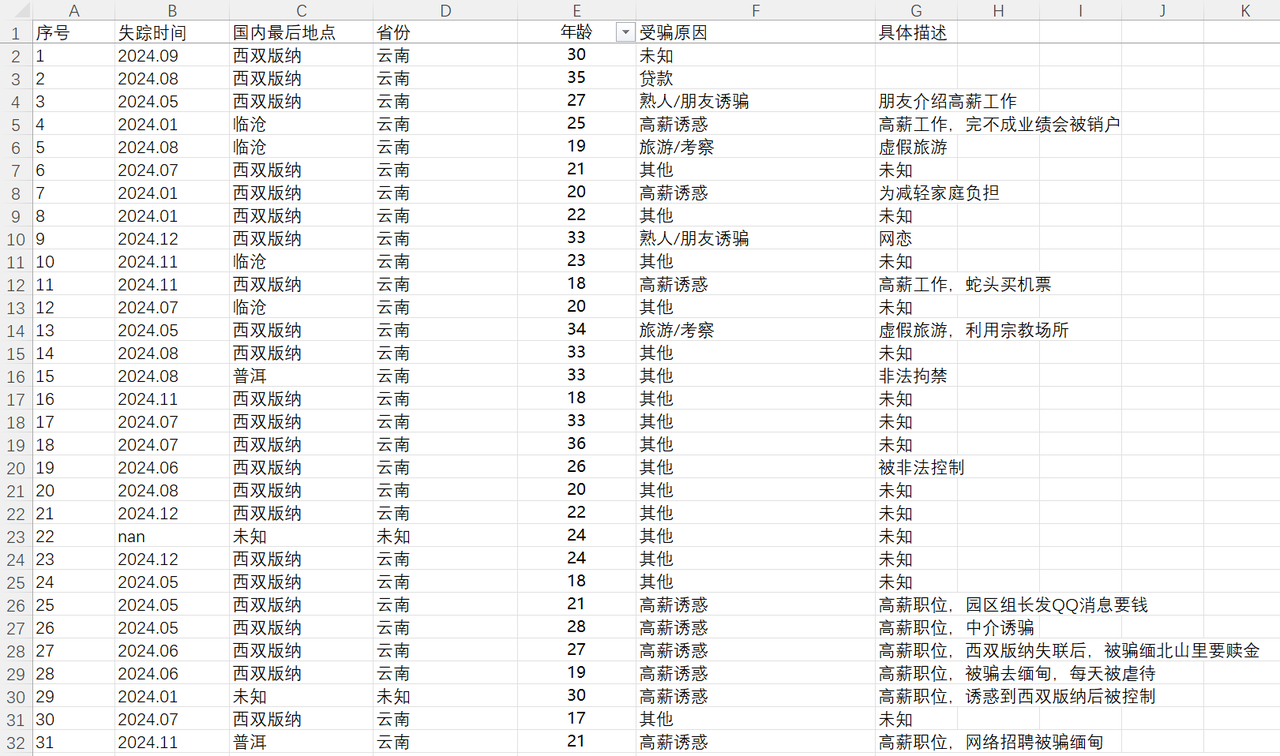
统计完成后的 Excel 文档
在 Excel 文档中对数据进行筛选统计,得到可视化的原始数据: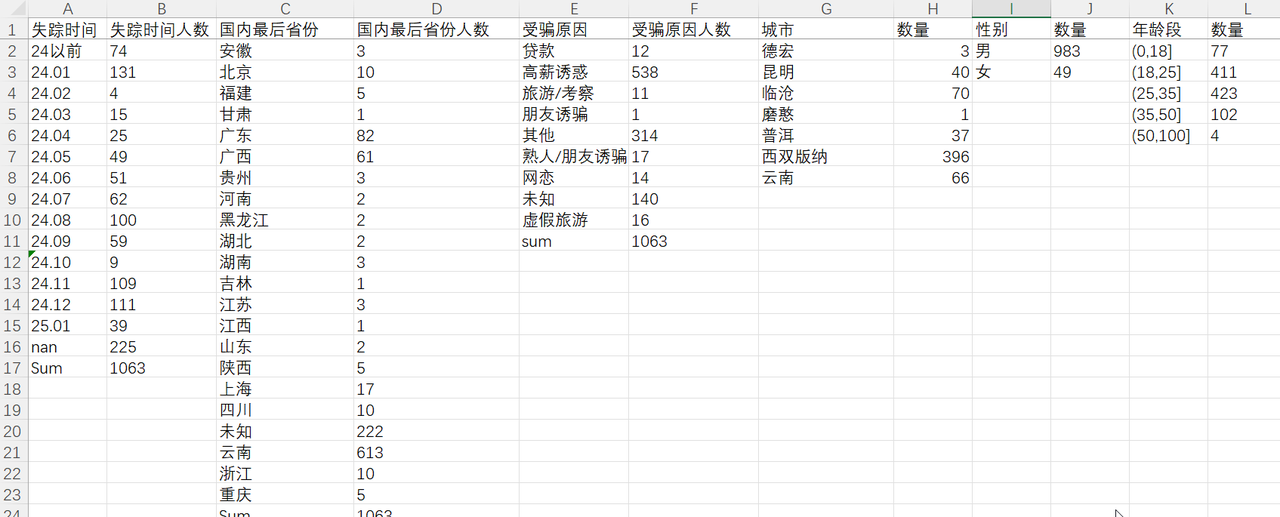
Excel 数据筛选统计结果
第三步:Tableau 数据可视化和结论
使用 Tableau 对数据进行可视化,增加可读性,从图表中总结规律和画像。
典型画像: 95% 男性,80% 为 18–35 岁,72.53% 在西双版纳,88.49% 因高薪诱惑受骗。
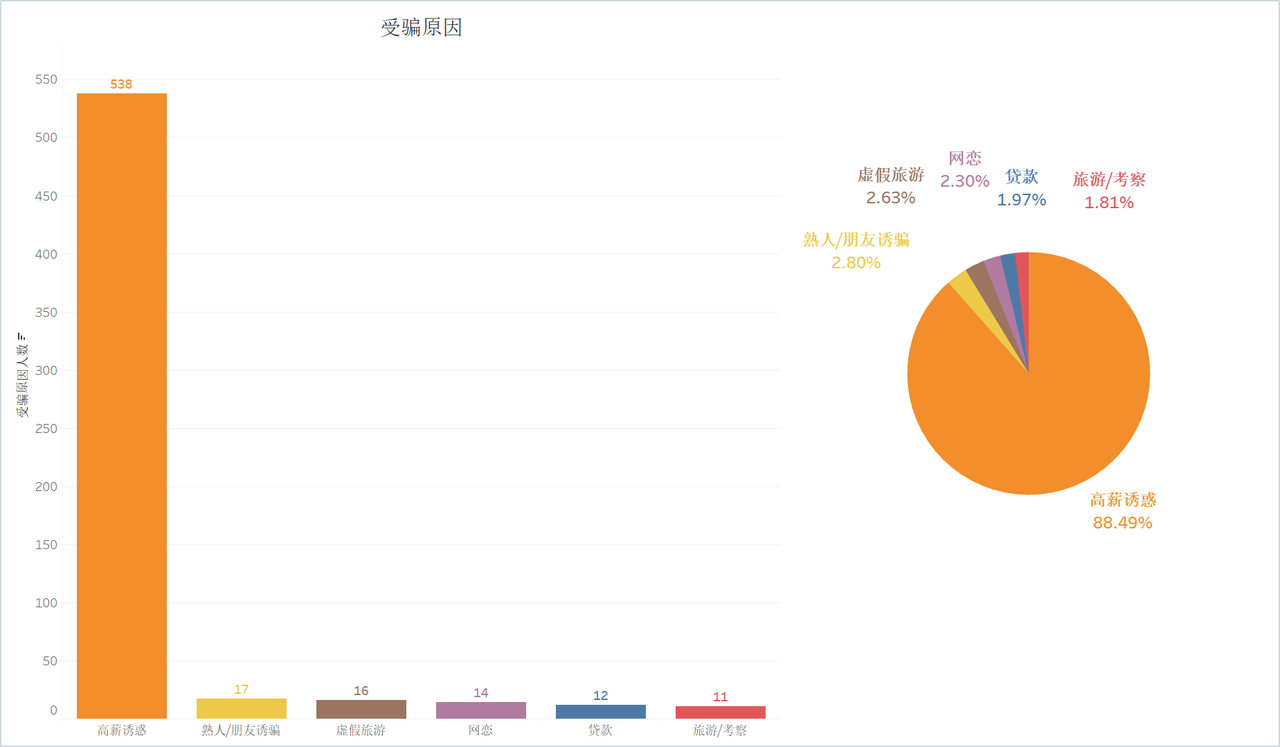
受骗原因-人数-柱/饼图
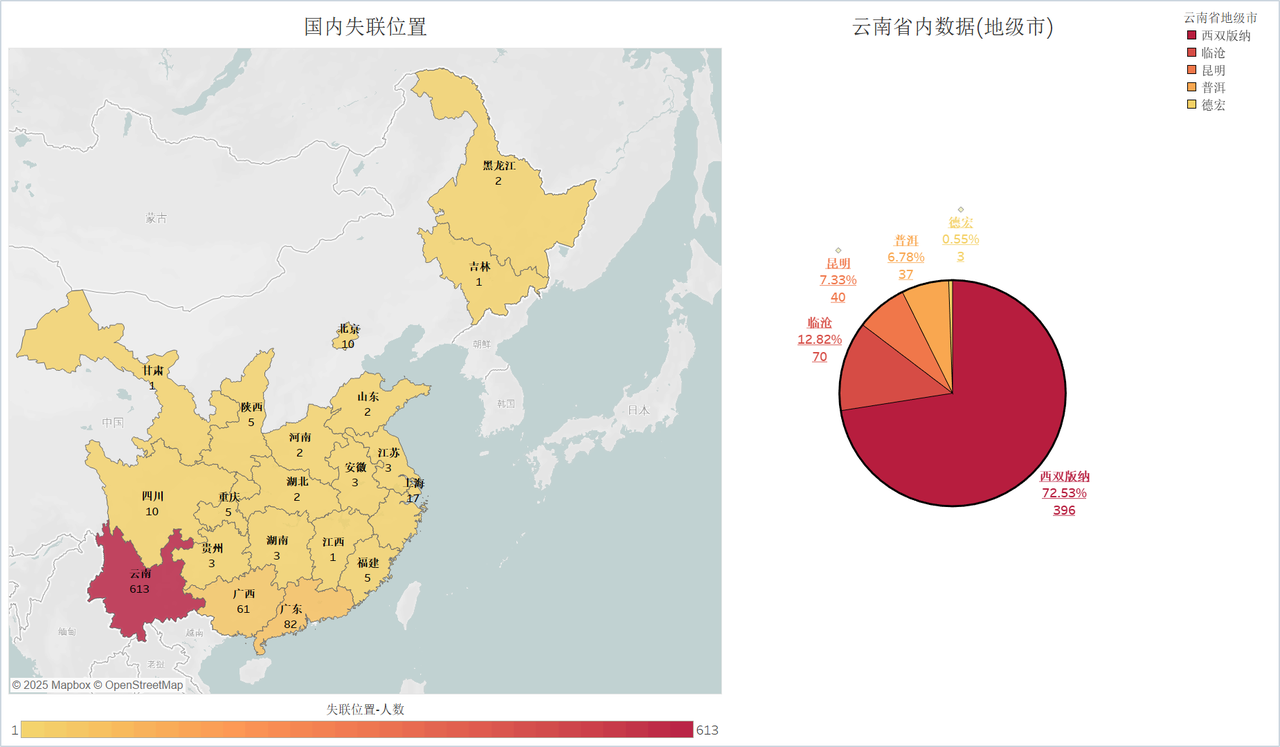
国内失联省份 & 云南省内城市位置-人数地图/饼图
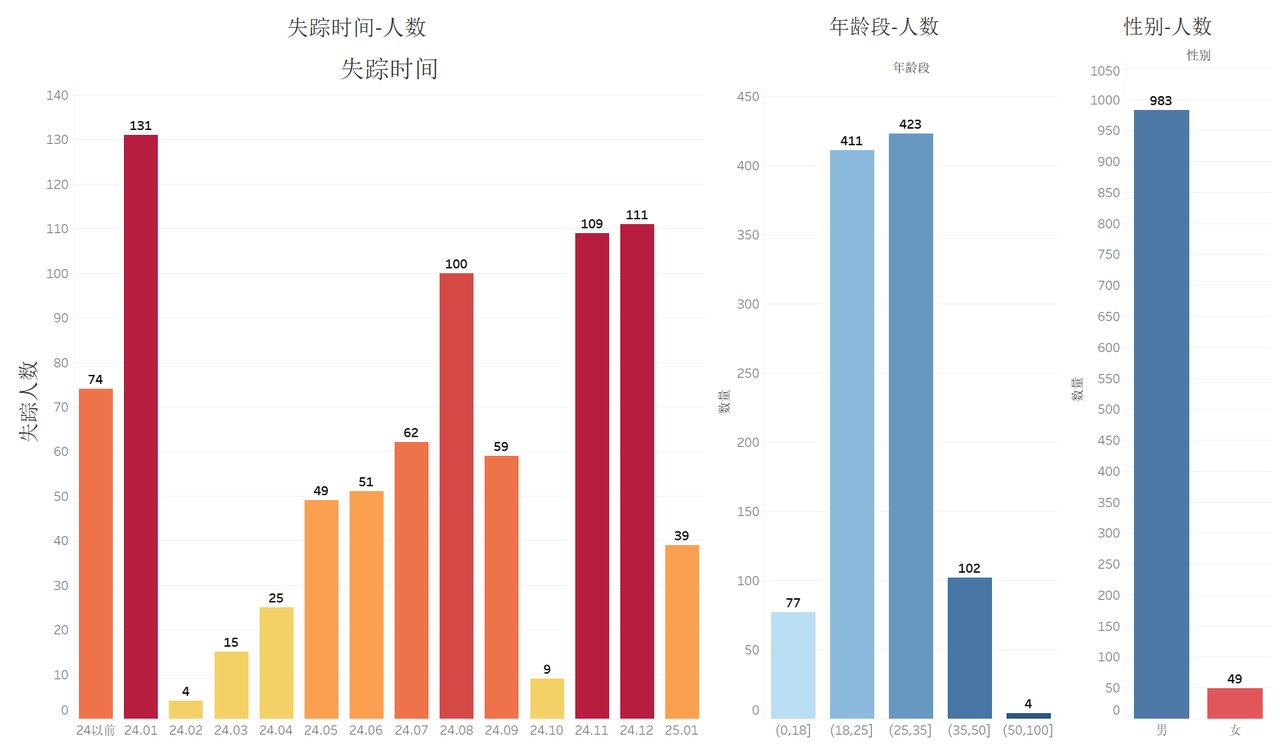
失踪时间/年龄段/性别-人数柱状图