本文写于26.3.30 7:53pm-9:40pm
前言
书接上回,在第一篇中,我们阐述了软件开发的基础生态,而在AI时代,模型不再只是工具,而是开发者可以调度的“基础设施”。
这一章是模型介绍篇,本文不会简单介绍模型,而是尝试回答一个更关键的问题: 在一个由不同国家、不同公司控制的AI世界中,我们该如何构建自己的能力体系?
模型能力的时局分析
在独立测评AI模型的第三方平台https://artificialanalysis.ai/ 可以看到一个供参考的模型供应商的排行榜
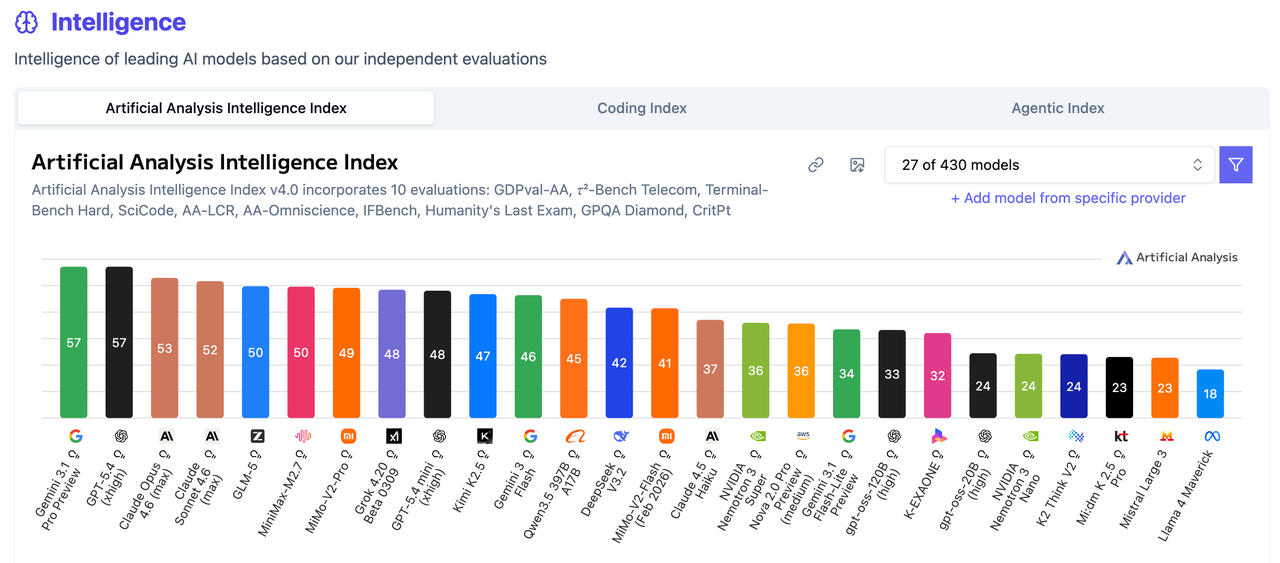
| 排名 | 模型 | 公司 | 国家 | 阵营 |
|---|---|---|---|---|
| 1 | Gemini 3 Pro | 🇺🇸 美国 | Big Tech | |
| 2 | GPT-5 (High) | OpenAI | 🇺🇸 美国 | Frontier Lab |
| 3 | Claude Opus 4.6 | Anthropic | 🇺🇸 美国 | Frontier Lab |
| 4 | Claude Sonnet 4.6 | Anthropic | 🇺🇸 美国 | Frontier Lab |
| 5 | GLM-5 | 智谱AI (Zhipu) | 🇨🇳 中国 | 大模型创业公司 |
| 6 | MiniMax M2.7 | MiniMax | 🇨🇳 中国 | 创业公司 |
| 7 | MiMo-V2-Pro | 小米AI | 🇨🇳 中国 | 大厂 |
| 8 | Grok 4.2 | xAI | 🇺🇸 美国 | Elon系 |
| 9 | GPT-5 mini | OpenAI | 🇺🇸 美国 | Frontier Lab |
| 10 | Kimi K2.5 | 月之暗面 (Moonshot) | 🇨🇳 中国 | 创业公司 |
| 11 | Gemini 3 Flash | 🇺🇸 美国 | Big Tech | |
| 12 | Qwen 3.5 397B | 阿里巴巴 | 🇨🇳 中国 | Big Tech |
| 13 | DeepSeek V3 | DeepSeek | 🇨🇳 中国 | 创业公司 |
| 14 | MiMo-V2 Flash | 小米 | 🇨🇳 中国 | 大厂 |
| 15 | Claude Haiku 4.5 | Anthropic | 🇺🇸 美国 | Frontier Lab |
| 16 | NVIDIA Nemotron | NVIDIA | 🇺🇸 美国 | Big Tech |
| 17 | Amazon Nova | AWS | 🇺🇸 美国 | Big Tech |
| 18 | Gemini Flash Lite | 🇺🇸 美国 | Big Tech | |
| 19 | gpt-oss-120B | OpenAI / 开源系 | 🇺🇸 美国 | Open-ish |
| 20 | K-EXAONE | LG AI | 🇰🇷 韩国 | 企业AI |
| 21 | gpt-oss-20B | OpenAI | 🇺🇸 美国 | Open-ish |
| 22 | NVIDIA Nemotron Nano | NVIDIA | 🇺🇸 美国 | Big Tech |
| 23 | K2 Think V2 | Kuaishou / 快手 | 🇨🇳 中国 | 大厂 |
| 24 | MiniMax K2.5 Pro | MiniMax | 🇨🇳 中国 | 创业公司 |
| 25 | Mistral Large 3 | Mistral | 🇫🇷 法国 | 欧洲独立 |
| 26 | Llama 4 Maverick | Meta | 🇺🇸 美国 | Big Tech |
第一梯队
第一梯队,俗称御三家的公司及其对应产品基本都来自美国,它们决定了AI能力的上限:
- Google—Gemini
- Anthropic—Claude
- Openai—Chatgpt
特点:
追求极限智能,定义能力上限
第二梯队
第二梯队的公司基本来自于中国,它们不追求最强,而是追求“足够强 + 足够便宜”。提供前沿、价格优惠的解决方案。
- 深度求索—DeepSeek
- 阿里巴巴—Qwen
- 月之暗面—Kimi
- 稀宇科技—MiniMax
- 智谱—GLM
特点:
用成本优势快速占领市场
其他扩展势力
- xAI(Grok)
- NVIDIA(Nemotron)
- Amazon(Nova)
- Meta(Llama)
特点:
通过云、GPU或社交入口绑定用户
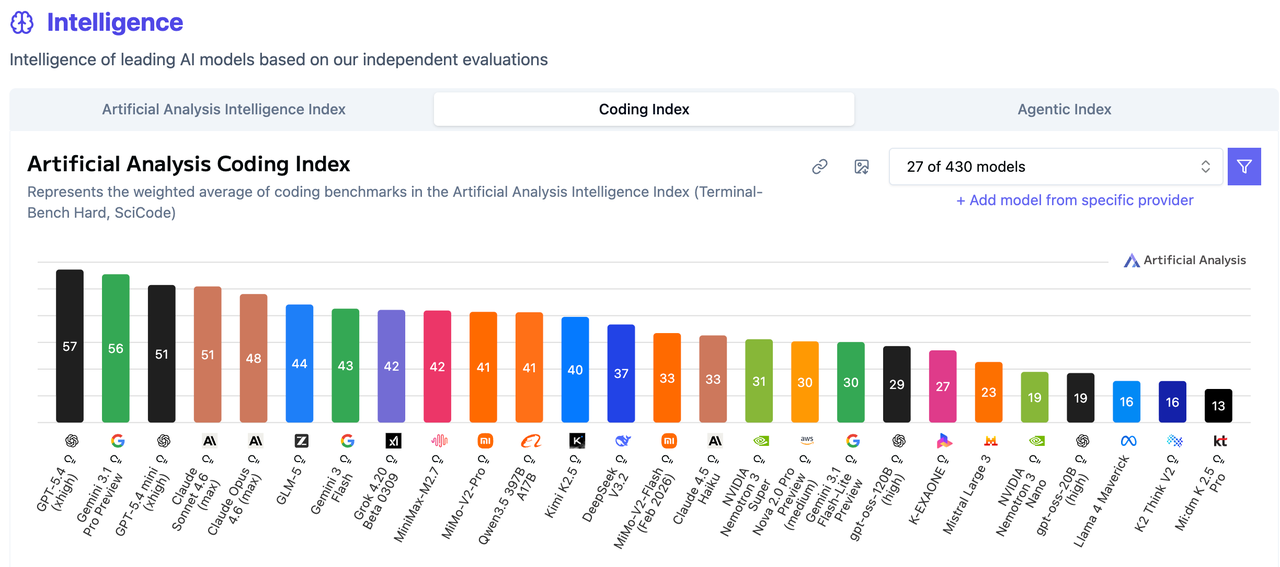
编程能力的对比
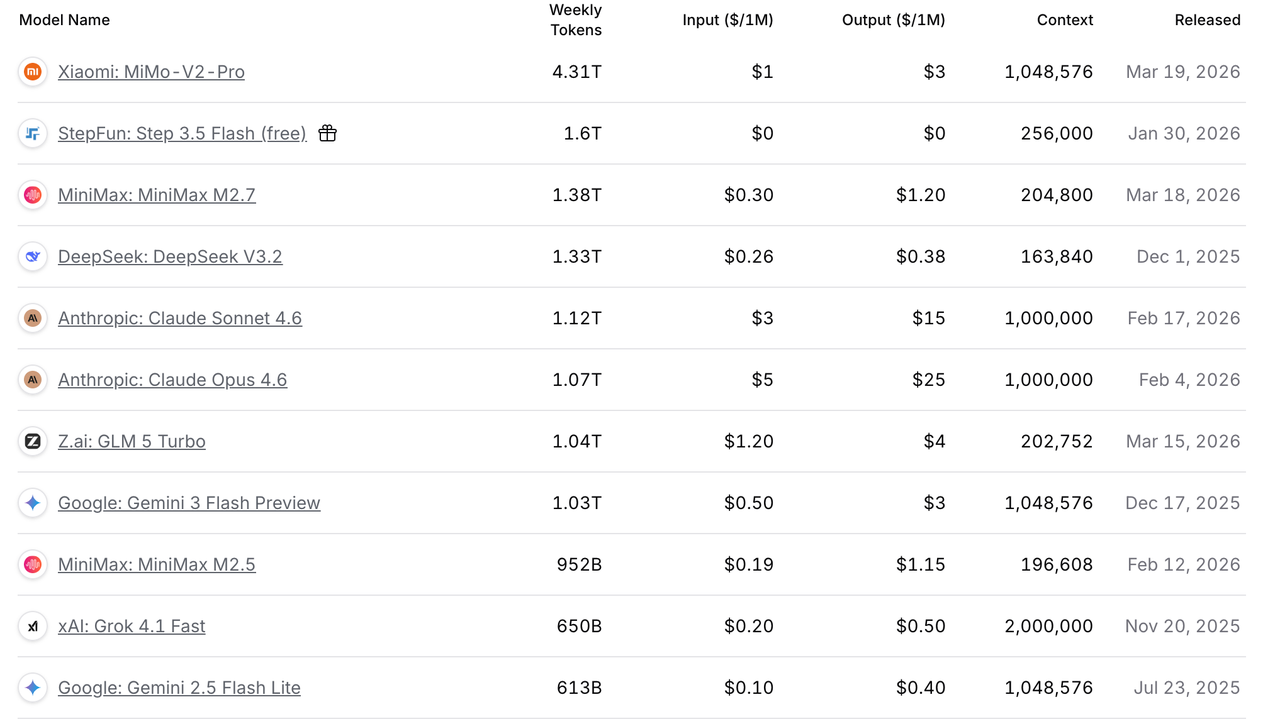
订阅方式汇总
Ai模型的算力是驱动各种Ai能力的基础,计费基础单位是Token,可以理解为AI世界的“电力单位。
模型厂商提供的不是功能,而是算力本身。谁掌握算力,谁就掌握生产力。
API调用
按量付费———相当于厂商给你接一条电线,用多少给多少钱。是所有的厂商都支持的付费方式
会员订阅
Google Gemini、Anthropic Claude、Openai Chatgpt支持的计费方式。
标准版会员订阅的价格,御三家都是20美刀一个月,可以获得网页版会员权益,以及AI编程的额度。
例如:Openai的Plus订阅会额外给予Codex(Chatgpt官方的编程Agent)的使用配额,以每5小时和每周限定额度的方式限制,同样的Anthropic也会提供Claude code的额度,Google会给予Antigravity的额度

参考链接:
- https://chatgpt.com/zh-Hans-CN/pricing/
- https://claude.com/pricing
- https://gemini.google/subscriptions/
Coding Plan
在Openclaw爆火后,极高的燃烧Token速度让用户们出现了Token慌,因此国内厂商顺势出台了Coding Plan的订阅包模式,通过包月限额的资源配置方式,给到用户一个廉价可靠的Token解决方案。
Coding Plan的出现,本质上是AI从“按量计费”走向“基础设施化”的标志。类似于电力从按次收费变为包月供电,开发者可以在一个可控成本范围内持续调用AI能力。
这意味着AI开始从“工具”变成“可持续供给的生产资源”
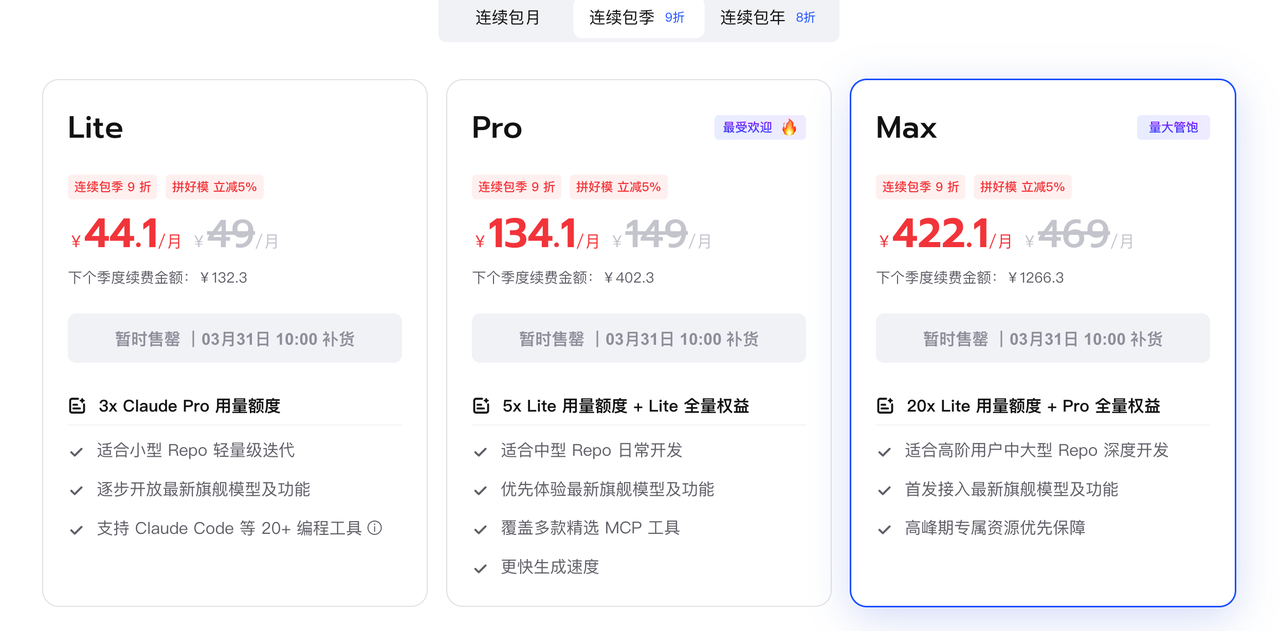
Coding Plan也是控制开发成本的最佳选择,如果有需要购买Minimax或者GLM的Coding Plan的朋友,可以点击下方我的邀请链接,获取GLM5%或者Minimax 10%的价格折扣优惠
https://platform.minimaxi.com/subscribe/token-plan?code=H5mFhfRxqH&source=link
https://www.bigmodel.cn/glm-coding?ic=PH3OZYF5I9
中转站
由于美国出口管制体系,中国大陆和港澳目前都不支持御三家的订阅,因此可以采用Openrouter(https://openrouter.ai/) 或者Curosr这样有信誉的第三方中转站或者聚合商获取顶级的API服务。
⚠️ 需要注意的是,通过中转服务获取模型能力虽然在短期内可行,但在监管逐步加强的背景下,其稳定性和长期可持续性存在不确定性。
因此在架构设计上,应避免对单一地区或单一供应商形成依赖。
不过26年3月开始, 美国对API调用的限制也愈发严格, 因此读者请不要将所有的Ai供应服务都限定在一个地区, 增加灵活性。
其他供应商
除了上述供应方式以外,还有其他个人第三方供应商通过反代等灰色方式获取算力,读者请自行鉴别,在成本控制和隐私泄漏之间做好权衡。
⚠️非官方和大品牌的供应商可能会将接收到的所有信息都打包倒卖,注意信息安全!
总结
在AI时代,开发者的核心能力正在发生变化。
不再是单纯“写代码”,而是:
- 理解模型能力
- 控制成本结构
- 设计可持续的技术组合
未来的开发者,更像“调度算力的人”,而不是“写代码的人”。
在这个过程中,真正的竞争优势,不来自于某一个模型,而来自于你如何使用它们。